Production ML —
from data to deployed model.
Computer vision, predictive ML, NLP, and LLM integration. We ship models that hit accuracy targets in production — not just in notebooks — with the MLOps to keep them running as the world changes.
Models are easy. Production ML is hard. We engineer for the gap between notebook and reality.
ML used to mean researching architectures from scratch.
Now it means assembling production systems from pre-trained foundations.
CNNs dominate vision. RNNs dominate sequences. Custom architectures everywhere.
BERT, GPT-2/3, ResNet, YOLO. Transfer learning becomes default — train less, fine-tune more.
CLIP, Segment Anything, DALL-E, Stable Diffusion. Multimodal arrives. Open weights matter.
MLOps mainstream. Fine-tuning is easy. Edge deployment standard. Vision models on phones.
Small fine-tuned models everywhere. Observable. Governed. Cost-engineered for scale.
What we deliver.
Four capabilities. Vision is often the most visible — but we build across the ML stack, picked by what your problem actually needs.
Computer Vision
Object detection, classification, segmentation, OCR, video analytics. Defect detection on production lines, medical imaging, visual search, document AI — built on YOLO, Segment Anything, OpenCV, and custom architectures.
Predictive ML
Time-series forecasting, anomaly detection, classification, recommendation. Demand forecasting, predictive maintenance, fraud detection, churn modeling — with proper validation and production monitoring.
NLP & LLM Integration
RAG-grounded answers, classification, extraction, summarization. Fine-tuning LLMs for domain accuracy. Clinical NLP, contract analysis, support automation — with structured outputs and evals.
MLOps & Production
Training pipelines, model versioning, deployment, observability, drift detection, retraining. The boring infrastructure work that turns a notebook prototype into a system that runs reliably.
A 5-stage methodology — data first, model second.
Most ML projects fail at framing or data, not at modeling. We start where the leverage is.
Problem framing
What kind of ML — vision, predictive, NLP, custom? What's the business metric? What's acceptable accuracy? Most ML projects fail at this step, not the modeling step.
Data audit
Quantity, quality, labels, drift. The model is only as good as the data. For vision: annotation quality and class balance. For NLP: corpus relevance. We audit before we train.
Model selection
Off-the-shelf vs fine-tuned vs custom. Start with pre-trained (YOLO, GPT-4, BERT). Fine-tune when generic doesn't fit your domain. Custom architectures only when nothing else works.
Production engineering
Latency budgets, cost per inference, monitoring, fallbacks. The boring engineering work where most ML projects die between notebook and reality.
Eval + iteration
Production data shapes the next model. Continuous monitoring, drift detection, periodic retraining. ML is not "ship and forget" — it's "ship and watch."
Pick the pattern that matches your input.
The right ML approach is driven by what data you have — not by what's trendy. Here's the four-way decision.
Computer Vision
Tasks involving images or video
Predictive ML
Structured data + a forecast or score
NLP / LLM
Text input, text or structured output
Multimodal / Custom
Multiple input modalities or custom architecture
The tools we use — and why.
Framework choice driven by problem fit, ecosystem maturity, and team productivity — not vendor preference.
Frameworks
Computer Vision
NLP & LLMs
MLOps & Production
Cloud ML
Ranges we typically deliver.
Numbers vary with the problem. Vision tasks tend toward higher accuracy; predictive tends toward broader cost reduction. Here's what we typically see in production.
What we'd ship for your industry.
ML patterns shift with the regulatory, latency, and data constraints of each vertical. Here's how we approach each.
Manufacturing
Real-time defect detection on production lines. Visual quality control. Component identification and counting. Predictive maintenance from sensor and image data. Edge deployment on factory hardware with sub-50ms inference for inline quality gates.
Healthcare
Medical imaging analysis (radiology, pathology, dermatology). Clinical NLP for documentation, coding, and decision support. HIPAA-aligned pipelines with audit logs and human-in-the-loop for diagnostic outputs. Custom models trained on de-identified institutional data.
Retail & E-commerce
Visual search and product matching from photos. Demand forecasting per SKU and channel. Personalization and recommendation engines. Content moderation at scale. Vision + structured data + LLM working together.
Operations & Logistics
Document AI and OCR for invoices, customs, shipping labels. Anomaly detection across telemetry. Route optimization with predictive ETAs. Damage detection from photos. Predictive maintenance on equipment.
ML systems that can be audited.
Model versioning + audit
Every model logged with training data, code version, eval scores, deployment date. Replay any prediction. Roll back to any version.
Bias + fairness checks
Subgroup metrics, fairness audits, distribution monitoring. Catch bias before it ships and after as data drifts.
Data governance
PHI/PII handling, retention policies, training-data lineage. Compliance posture (HIPAA, GDPR, SOC 2) designed in from day one.
Production observability
Per-prediction logs, latency tracking, accuracy drift detection, cost dashboards. ML you can debug at 3am.
We ship ML, not just train it.
The notebook accuracy is the start of the work, not the end. Most ML projects fail at deployment, monitoring, and the long tail of edge cases. We engineer for that gap.
A clean dataset with a simple model beats messy data with a fancy architecture almost every time. We audit data first, model second.
Pre-trained models (YOLO, GPT-4, BERT) are excellent baselines. Fine-tune when they fail your domain. Custom architectures only when nothing else works.
Eval suites in CI. Drift detection in production. Per-segment accuracy tracking. Without these, ML systems silently degrade and nobody notices until customers complain.
ML in production.
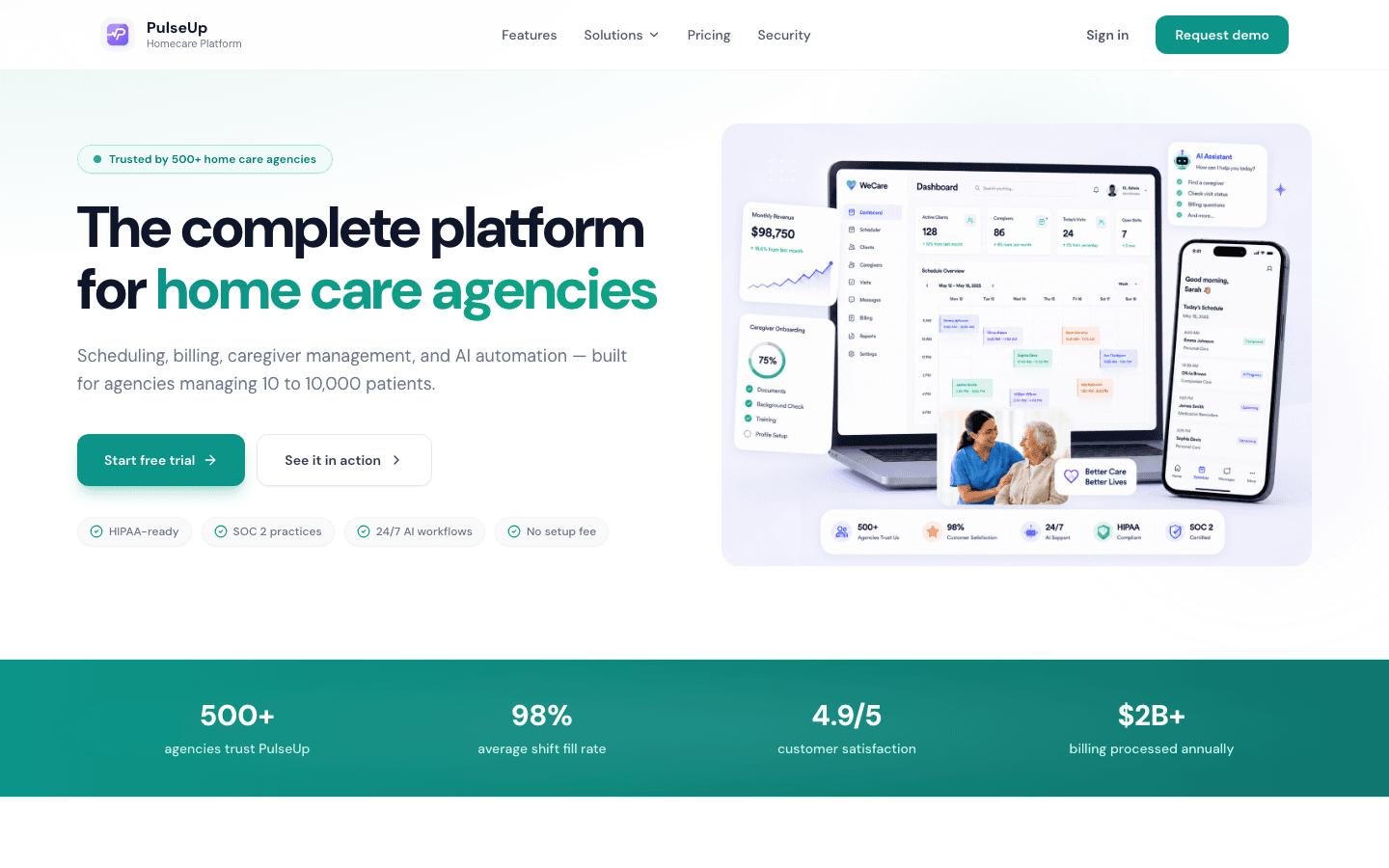
AI Automation for Modern Care Agencies — PulseUp Health
An AI-native home care management platform that automates scheduling, billing, payroll, and family communication for agencies running 10 to 10,000 patients.
View case study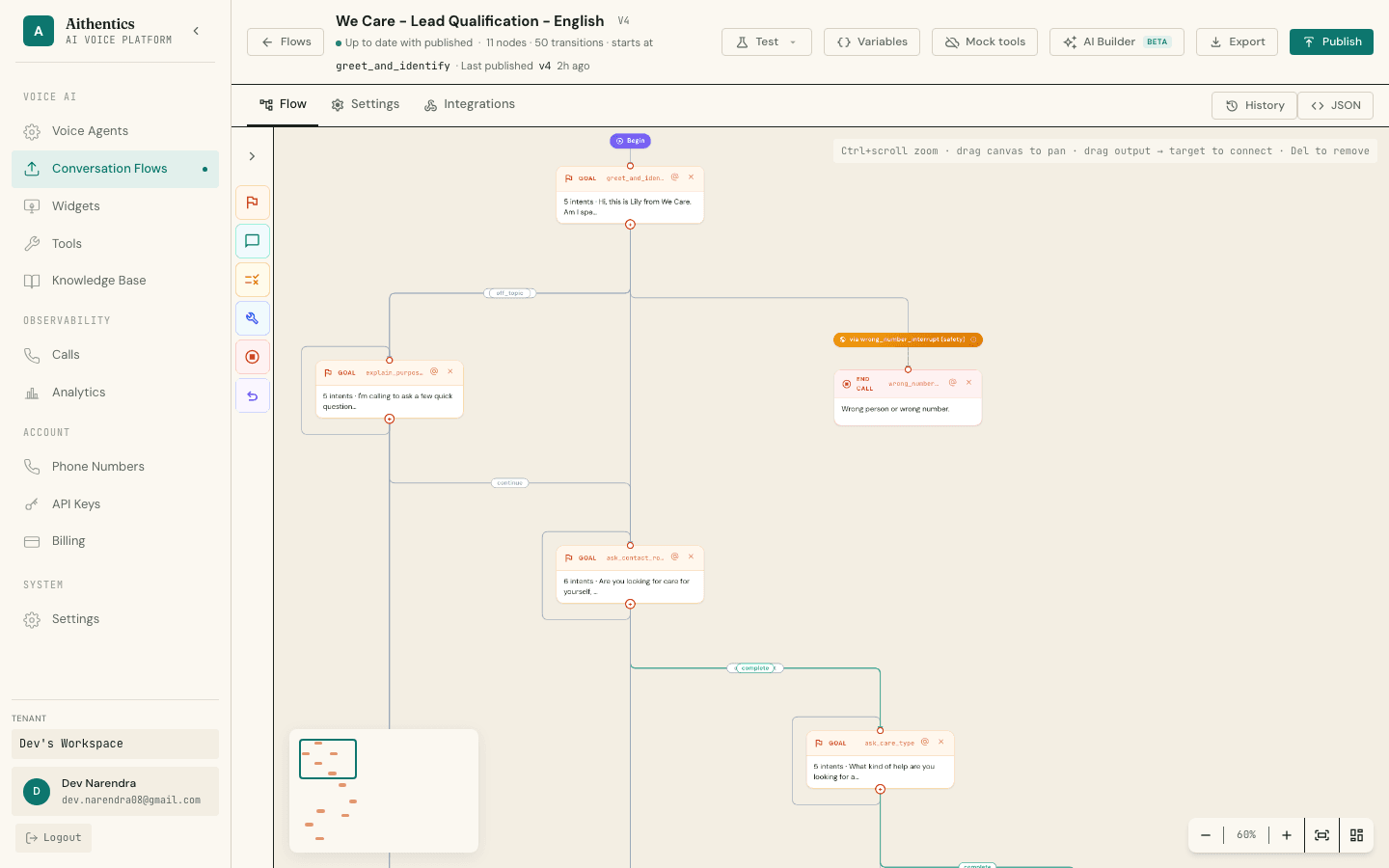
Voice AI Platform
A multi-tenant voice AI platform with a two-level orchestration architecture: a transport-bound audio layer and a turn-based cognitive engine that scales independently.
View case study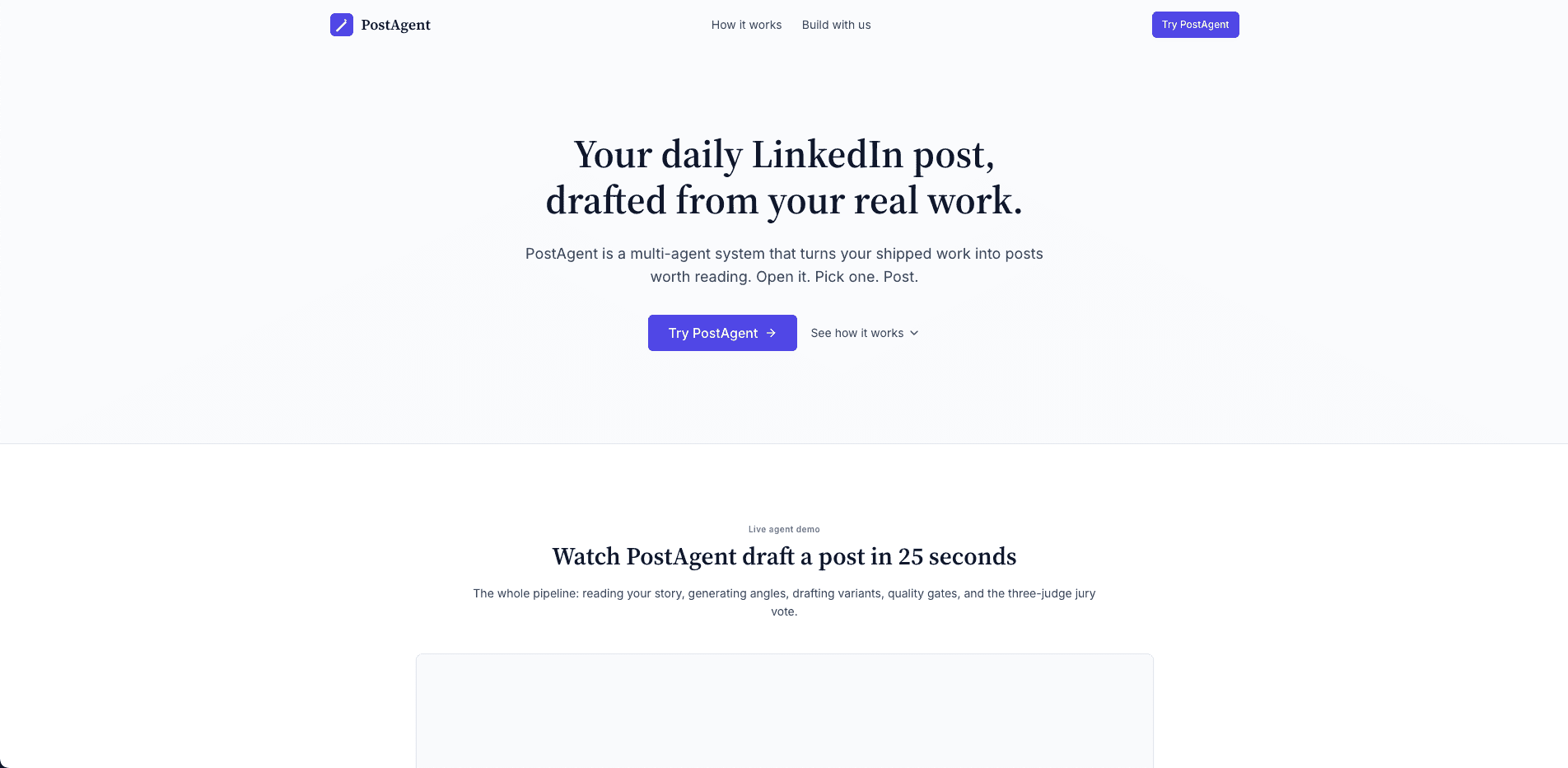
AI Agent for LinkedIn Content — PostAgent
A multi-agent system that turns your shipped work into LinkedIn posts. Reads your real activity, generates angles, drafts variants, runs quality gates, and picks winners with a three-judge jury.
View case study
Customer Support AI Assistant
An AI-native customer support assistant where specialized agents handle intent classification, knowledge-grounded responses, escalation routing, and ticket summarization — replacing tier-1 support load and accelerating tier-2 resolution.
View case studyHonest answers.
Strategy
Engineering
Engagement
Got an ML problem to ship to production?
Tell us the task — vision, NLP, predictive, multimodal. We'll come back with a scoped plan, baseline model, and a path to production within 4–8 weeks.
Book a Strategy CallTurn Your Vision IntoReality
Get a free consultation and discover how we can accelerate your product development with AI-powered solutions.
Launch 40% Faster
AI-powered development reduces time-to-market significantly
Scale with Confidence
Built for growth with enterprise-grade architecture
24-Hour Response
We'll get back to you within 24 hours with a detailed proposal